


Fujitsu optimiza el reconocimiento de vídeo basado en IA con una tecnología de compresión de alta calidad
Fujitsu Laboratories Ltd. ha desarrollado una tecnología para comprimir datos de vídeo de máxima definición y gran volumen al tamaño mínimo necesario, para que aplicaciones de reconocimiento de vídeo basadas en Inteligencia Artificial puedan ser implantadas, salvando uno de los principales frenos hasta ahora debido a las enormes exigencias de capacidad de cómputo y tiempo de proceso necesario que lo alejaba de los estándares del real time en el análisis a través de la nube. Fujitsu hace posible comprimir los datos de vídeo a sólo una décima parte del tamaño de los datos preparados con la tecnología de compresión convencional , destinada a la confirmación visual por humanos.
En los últimos años, ha habido un fuerte aumento en la demanda de análisis de IA de datos de vídeo en varias áreas de negocios. Se espera que la expansión del sistema de comunicaciones móviles de 5G, en particular, contribuya a un explosivo incremento en el número de imágenes de vídeo de ultra alta definición capturadas por cámaras (C2C), así como muchas imágenes tomadas en la calle (IoT) y en líneas de producción (IIoT).
Al desarrollar esta nueva tecnología de compresión, Fujitsu se centró en una importante divergencia en la forma en que IA y los humanos reconocen las imágenes. Es decir, la IA y los humanos tienden a diferir en las áreas de la imagen que se enfatizan como importantes, a la hora de reconocer personas, animales u objetos en los datos de vídeo. Por ello, la compañía ha desarrollado una tecnología para analizar automáticamente las áreas bajo los valores de IA y comprimir los datos al tamaño mínimo que esta puede reconocer. Esto hace posible analizar una gran cantidad de datos de vídeo sin comprometer la precisión del reconocimiento y, al mismo tiempo, reducir significativamente los costes operativos y de transmisión de datos. También se anticipa que la tecnología permitirá a los usuarios analizar la información de los vídeos de forma más avanzada, combinando múltiples datos de vídeo almacenados en la nube, datos de sensores y de rendimiento, como los de ventas.
Antecedentes y desafíos
En los últimos años, la tecnología para analizar imágenes usando IA se ha desarrollado rápidamente y se espera que sea una de las fuerzas impulsoras de la transformación digital en muchas empresas de diferentes sectores. Con la llegada de los sofisticados servicios móviles 5G en 2020, la demanda de análisis de IA aumentará aún más, acompañada por el uso creciente de cámaras 4K y 8K de ultra alta definición y grandes cantidades de datos de vídeo para aplicaciones que incluyen análisis de comportamiento en industrias manufactureras y de retail, así como reconocimiento facial masivo.
A pesar de esto, las demandas de procesamiento para técnicas de aprendizaje profundo utilizadas para el análisis de imágenes presentan desafíos considerables. Una técnica efectiva para asegurar la potencia tecnológica para hacer frente a estas tareas, es procesar en conjunto con la nube, pero dado que los datos de vídeo a menudo requieren muchos recursos, existe la necesidad de tecnología de alta compresión que pueda transmitir todos los datos de vídeo al cloud sin comprometer la calidad, para que el ancho de banda de la red no se sobrecargue.
Tecnología desarrollada
La compresión de vídeo reduce la calidad de la imagen dependiendo de la tasa de compresión, y si el área en la que se enfoca la IA se comprime excesivamente, la precisión del reconocimiento disminuye. Fujitsu ha desarrollado una tecnología de compresión de vídeo que analiza automáticamente el área de un objeto reconocido por la IA como material de análisis en una imagen de un marco de datos de vídeo, comprimiendo (²) la imagen con la calidad mínima requerida para el reconocimiento de cada área (H.265/HEVC) (Figura 1).
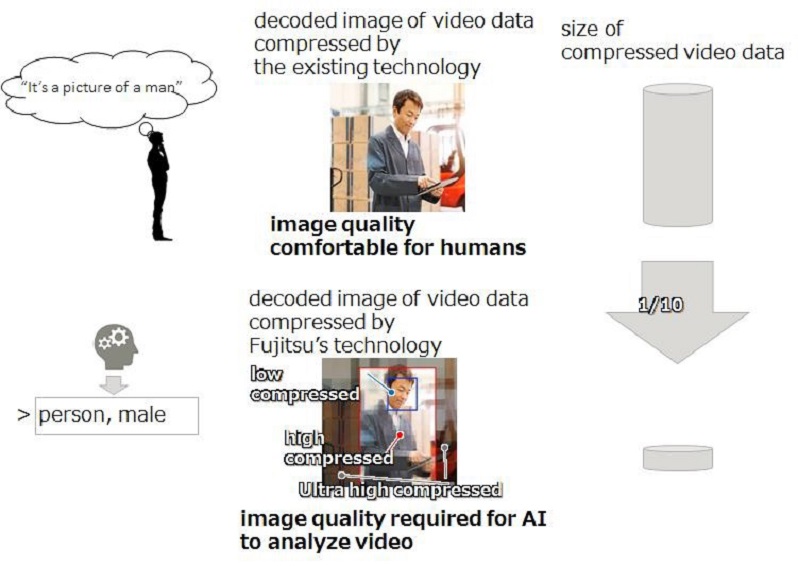
Al aplicar esta tecnología, el tamaño de los datos de vídeo se puede reducir significativamente, en comparación con las tecnologías de compresión convencionales, manteniendo la precisión del reconocimiento. Se trata de estimar automáticamente la ratio de compresión sin afectar la precisión del reconocimiento de IA.
El efecto de la degradación de la calidad de imagen específica de la compresión en la precisión del reconocimiento se analiza para cada área. La ratio de compresión que no afecta la precisión del reconocimiento se estima automáticamente en función de los resultados del reconocimiento de IA.
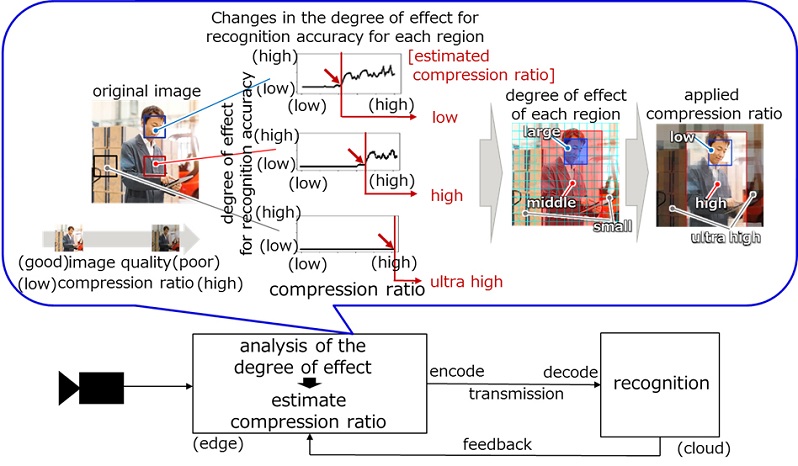
El grado de importancia de las características en el proceso de reconocimiento por parte de la IA se determina para todas las áreas, agregando los efectos en los resultados de reconocimiento, cuando se cambia la ratio de compresión de toda la imagen y también la calidad de la imagen. La tasa de compresión inmediatamente antes de que la precisión del reconocimiento se deteriore rápidamente en cada área, se estima como una tasa de compresión que no afecta la precisión del reconocimiento.
También retroalimenta los resultados de IA de imágenes sucesivas para aumentar la compresión al máximo que la IA puede reconocer. Al hacerlo, la tecnología logra una alta compresión de imagen, a la vez que mantiene la precisión del reconocimiento de IA.
Efecto
La tecnología recientemente desarrollada se aplicó a imágenes de vídeo tomadas por una cámara 4K de múltiples trabajadores empacando en una fábrica. Se confirmó que el tamaño de los datos podría reducirse a 1/10 del tamaño de los datos de la tecnología de compresión convencional, sin un deterioro en la precisión del reconocimiento. Se espera que esta tecnología se use para aplicaciones que no requieren un rendimiento estricto en tiempo real, así como para el análisis de datos de vídeo avanzados que combinan múltiples datos de vídeo almacenados en la nube, datos de sensores y datos de rendimiento, como los de ventas.
Planes futuros
Fujitsu Laboratories está evaluando esta tecnología en una variedad de casos y está llevando a cabo una investigación y desarrollo adicionales para mejorar aún más el rendimiento de la compresión. La multinacional espera comercializar esta tecnología para fines del año fiscal 2020 e introducirla en una variedad de aplicaciones para diferentes industrias, incluida su plataforma de servicio Colomina, una solución de industria manufacturera. Se puede hallar más información en la nota original en inglés.


